automagic-API
(five minute hack-and-tell version)
I data
I a good API
but the internet does not always love me back
Web scraping sucks to do by hand...
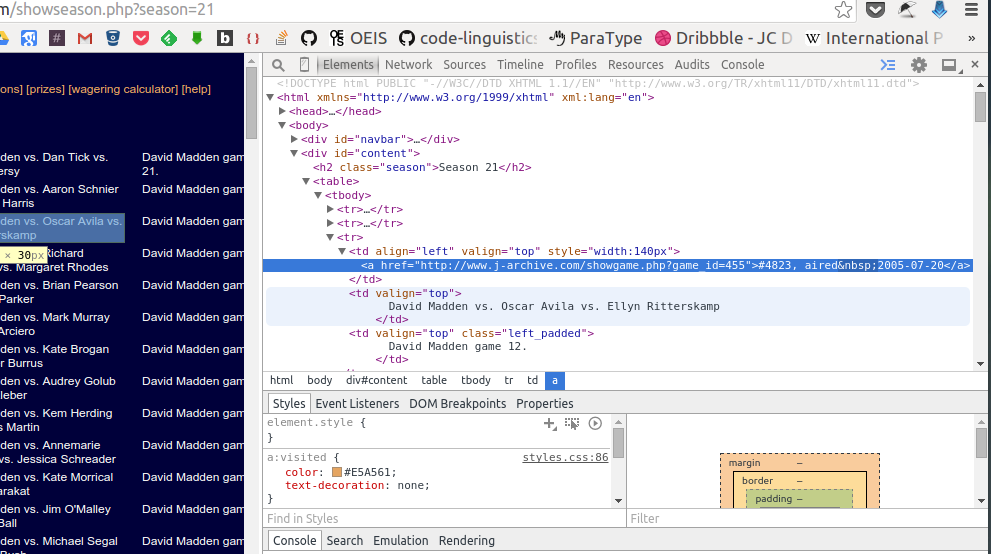
wouldn't it be awesome if we could automate some of it?
Examples from the J! Archive
Automagic-API!
builds an interactive API builder (so meta)Step #1: Download some sample pages
python construct_API_tree.py --name Jeopardy samples/jeo/*looks at the DOM "graph" from classes
{'category': 39,
'category_comments': 39,
'category_name': 39,
'clue': 183,
'clue_header': 180,
...removes redundant elements
search possibly repeated text, dropping
noborder possibly repeated text, dropping
...Builds an ugly tree
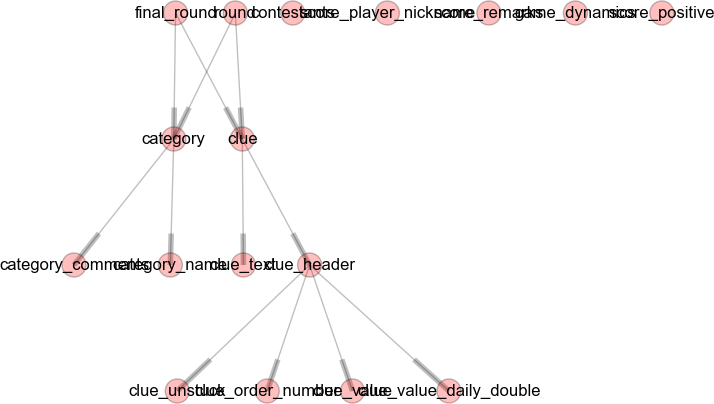
and the uses d3 to create a beautiful one!
Step #2: Select the DOM elements you want to keep
Step #3: Build the API
python build_API_from_tree.py samples/output_graph.svg samples/jeopardy.api{
"round": {
"category": {
"category_name": {}
},
"clue": {
"clue_text": {}
}
}
}Step #3: Automagic! Query the new API:
api = load_API(args.API)
url = "http://j-archive.com/showgame.php"
payload = {"game_id":4860}
req = requests.get(url,params=payload)
soup = bs4.BeautifulSoup(req.content,'html5')
data = dive(api, soup)And get wonderful data!
{u'final_round': [{u'category': [{u'category_name': [u'COMEDY INSPIRATIONS']}],
u'clue': [{u'clue_text': [u'Rodney Dangerfield credited this 1972 Best Picture Oscar winner for inspiring his most famous line']}]}],
u'round': [{u'category': [{u'category_name': [u'THE FAULT IN OUR STATES']},
{u'category_name': [u'FOOD & DRINK']},
{'category_name': [u'BETTER KNOWN BY ONE NAME']},
{'category_name': [u'TV VIOLENCE']},
{'category_name': [u'CAUTION, DECONSTRUCTION UNDERWAY']},
...So much more to do!
- Advanced API queries (flattening)
- Export API's to standalone BeautifulSoups?
- More fine-grained machine learning of bad DOM elements
- Apply to other DOM elements (id's?)
Thanks you!
Looking for an overpowered scientist turned analyst/developer? Let's talk!
travis.hoppe @ gmail.com