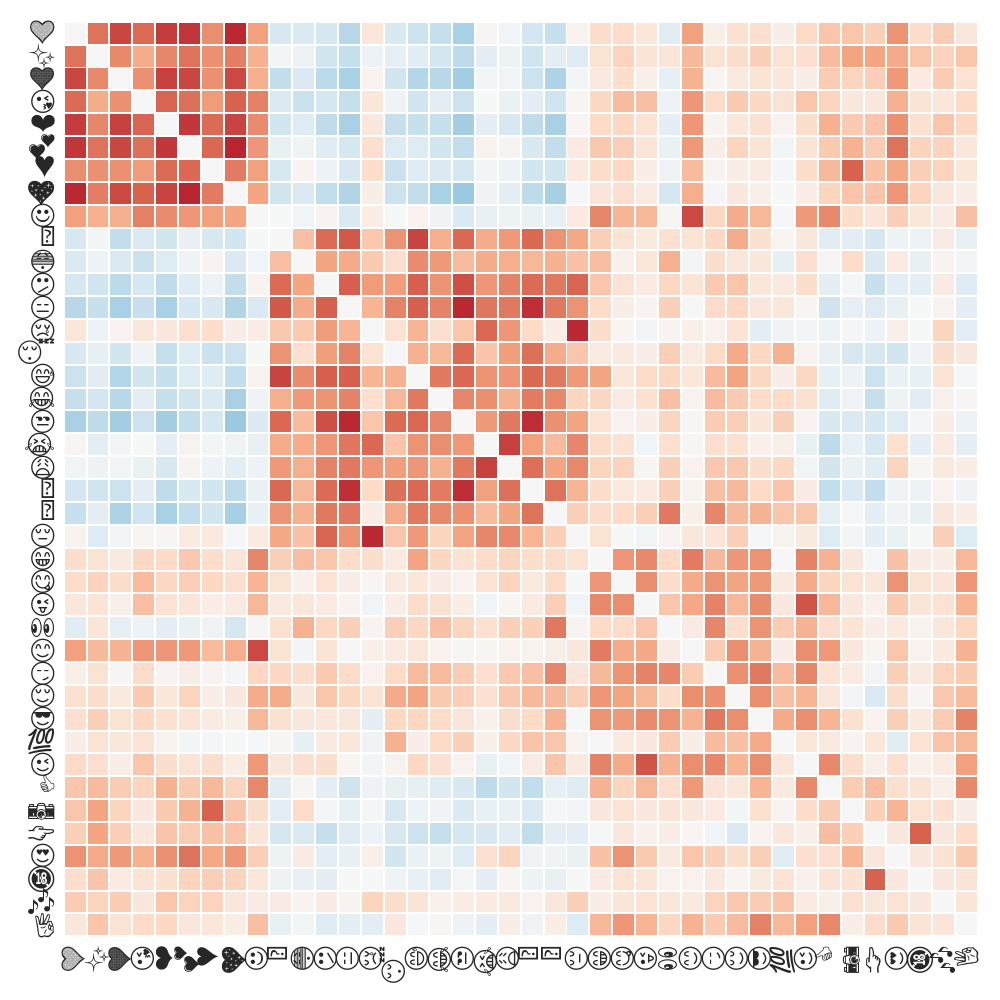
Emoji have synonyms and antonyms
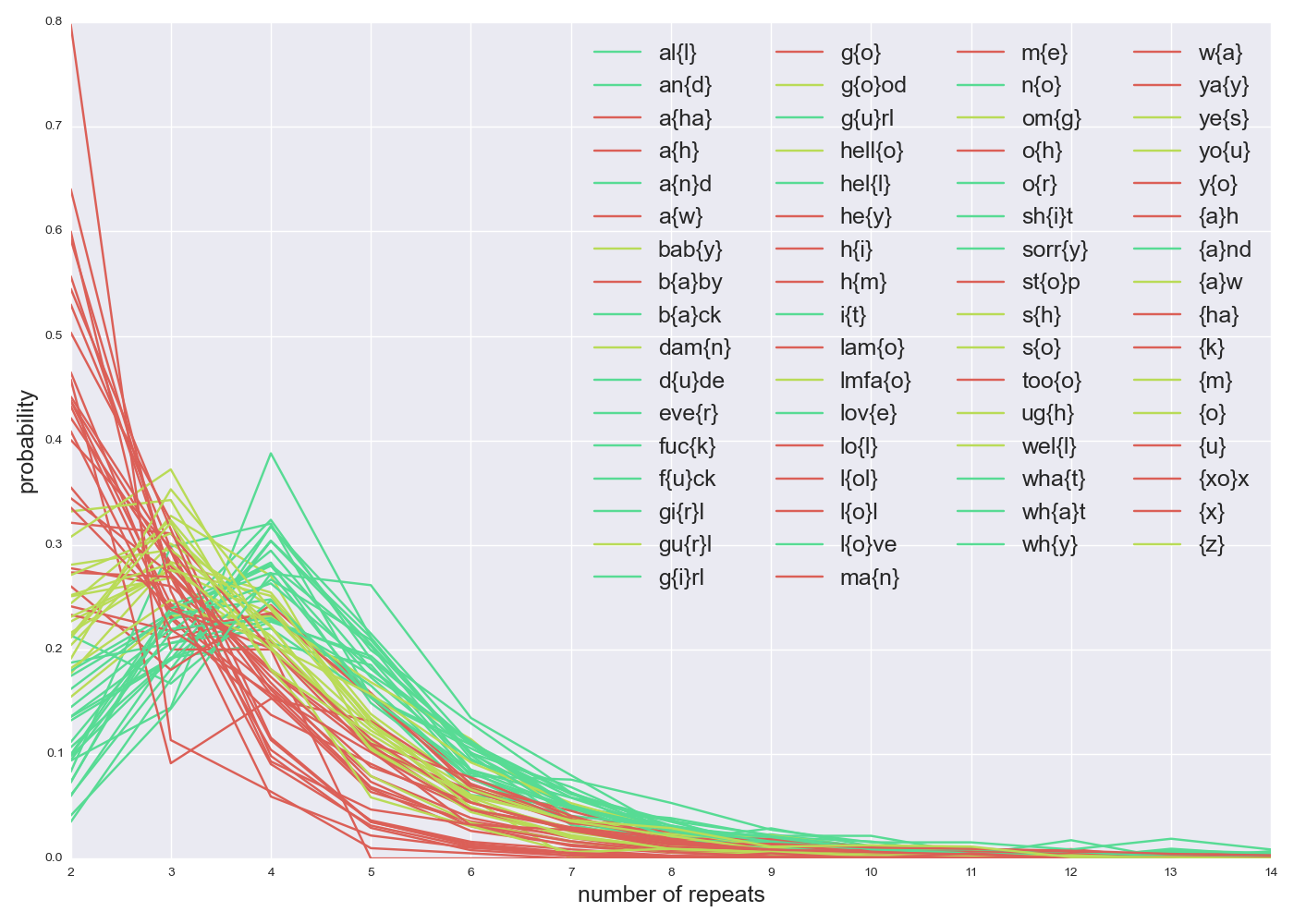
There is an optimal length to omggggggg
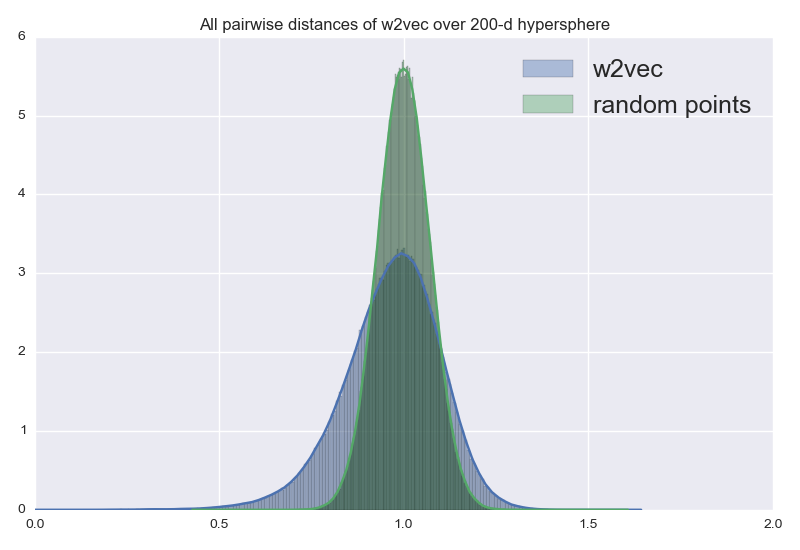
word2vec spreads vectors across the hypersphere
Polysemous emoji!

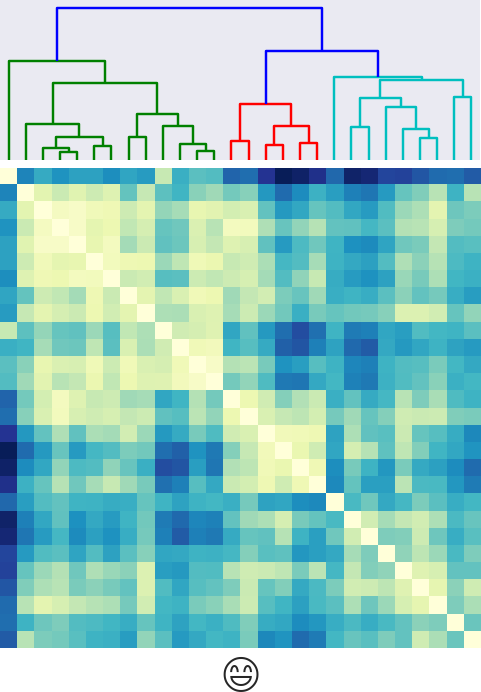
Sample tweets containing target emoji, compute mean w2vec of each tweet, run low order affinity propagation, cluster and interpret vectors near clusters.
What is a 🔑 ?
major success is key consistency communication knowledge growth life
or❤ 💜 @ 😘 ❣ 💛 💖 💞 💝
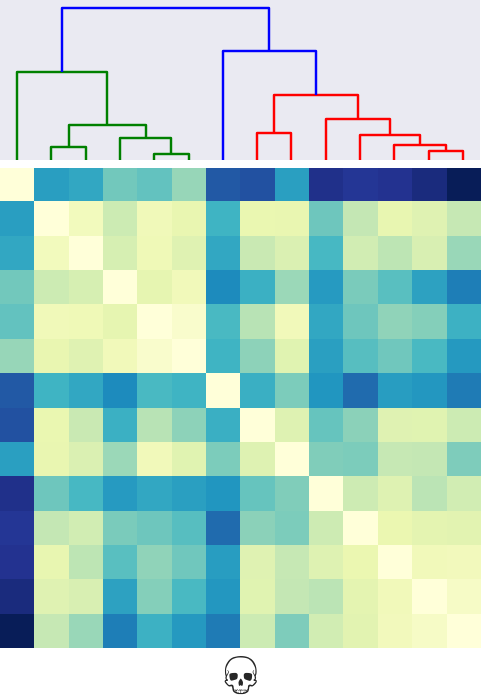
What is a 💀 ?