implementation MEDIUM : defense REASONABLE : hack-level CORPORATE
not RESTful?
Implement visitor control via $SESSIONS. Give every new visitor to the site a unique ID that you control and limit access with. Bonus, restrict user-agent.
REST API?
Require all meaningful data requests to go through OAuth2, cumbersome for new-comers and direct control over the data distribution.
WhiteHat3: Authentication
Create session ID's with headless browsers and simulate user-agents
Black Hat Warning: Poorly designed session states (that don't clear and hold large internal variables) can DoS your server!
BlackHat4: Data & time limits
implementation MEDIUM : defense REASONABLE : hack-level CORPORATE
Detection: high download rates or unusual traffic within a given timespan; all traffic from a single client or IP address.
Rate limit individual IP addresses or a specific id. Delay content delivery. Return HTTP 301, 40x or 50x errors (full list)
Don't emulate a browser, be the browser! Selenium ex.
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Firefox()
driver.get('http://www.google.com')
q = driver.find_element(By.NAME, 'q')
q.send_keys('Black Hat Data Wrangling')
q.submit()
Map post-filter md5sum to user data (not resistant to image changes). Impossible for user to know what is being stored!
import numpy as np
from scipy.ndimage import imread
from scipy.misc import imsave
jpg = imread("panda.jpg")
idx = np.random.uniform(size=jpg.shape) < 0.001
jpg[idx] += np.random.uniform(-2,2, size=idx.sum()).astype(np.uint8)
jpg[jpg<0] = 0
jpg[jpg>255] = 255
imsave("panda_new.jpg", jpg)
# Test on command line
# $ md5sum *.jpg
# bd1a44ba2111eb675e78935d4d5cc186 panda.jpg
# 672c6dbf03828ea50a70bc81e19bfd69 panda_new.jpg
General steganography
Works for any lossy format (mp3, gif, etc...) For tabular data, hide identification in NULL fields that can be easily removed. Perturb date-times by seconds in data records and save the offset.
Honeypots
If a bot or persistent downloader is identified, feed them faulty data. Continually degrade image quality sent as function of DL's. Remove rows, or return records not found with increasing frequency.
WhiteHat8: Honeypots & Steganography
Download data multiple times from different origins.
Run diff commands to suss out data that changes by IP and user.
Sanitize data by rejecting fields and entries that change with alternative DLs.
Modify image to remove steganography (apply same trick twice!)
BlackHat9: Remove markup metadata
implementation HARD : defense REASONABLE : hack-level CORPORATE
Two ways:
1. Break the standard UX design.
2. Remove proper HTML/CSS markup.
Organized webpage = Organized data = Easy rip
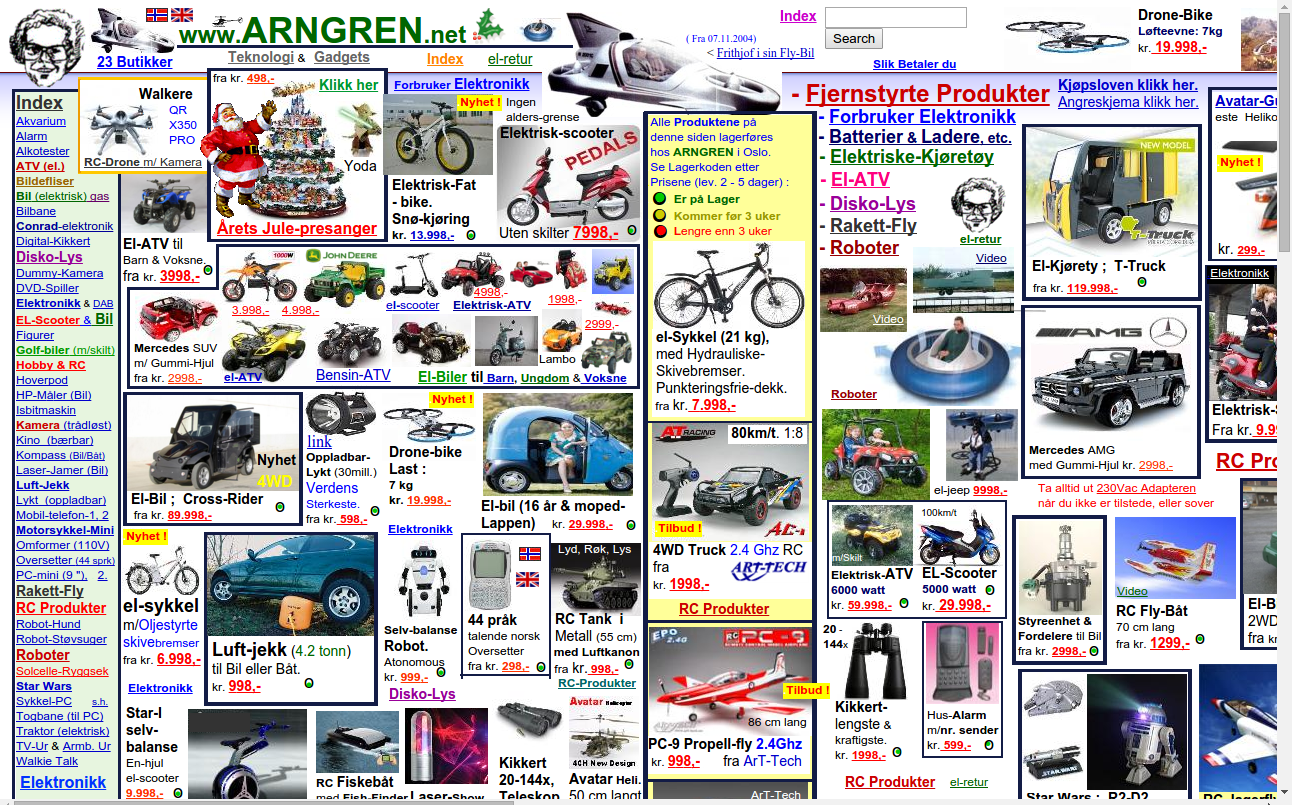
Eschew all user design and layer components dynamically. Example: http://arngren.net/
function addLink() {
//Get the selected text and append the extra info
var selection = window.getSelection(),
pagelink = '<br /><br /> Read more at: ' + document.location.href,
copytext = selection + pagelink,
newdiv = document.createElement('div');
//hide the newly created container
newdiv.style.position = 'absolute';
newdiv.style.left = '-99999px';
//insert the container, fill it with the extended text, and define the new selection
document.body.appendChild(newdiv);
newdiv.innerHTML = copytext;
selection.selectAllChildren(newdiv);
window.setTimeout(function () {
document.body.removeChild(newdiv);
}, 100);
}
document.addEventListener('copy', addLink);
A PDF is a collection of symbols drawn on a page. Draw `c` here, draw `a` there, etc. A PDF reader only knows what a letter is because it maps to a specific character code in the font. Simply create a new font that lies about its mapping.
Multiple fonts can be used to improve the "encryption" process, one font per character gives a one-time pad!
WhiteHat12: Text remapping
For Javascript remapping use a headless browser. For hidden spans, learn and write custom rules to remove the offending page elements. For font remapping...



















{kind=link}