Sequence to structure prediction
Sequence Multiple Sequence Alignment ...DTSGVQGIDVSHWQGSINWSSVKSAGMSFAYIKATEGTNYKDDRFSANYTNAYNAGIIRGAYHFARPNASSGTAQADYFASNGGGWSRDNRTLPGVLDIEHNPSGAMCYGLSTTQMRTWINDFHARYKARTTRDVVIYTTASWWNTCTGSWNGMAAKSPFWVAHWGVSAPTVPSGFPTWTFWQYSATGRVGGVSGDVDRNKFNGSAARLLALANNTA
----DYGIDVSSSTSQSQWSCLAGKN-QRAIIQVWSGGYGLNSQASSIISAAKSAGFQVDVYAFLCNQCSPSSNVIQQIVNSL---GGQFGT--LWIDVEQCS---GCWG-DVNDNAAFVAEAVQTAAS-LGVTVGVYSSLGEWPQTVGSL-SSLSSYPQWYAHYDGVAASQYGGWDNPEMKQYVGNTNECGV--SVDLDYYG--------------
----ELGIDVSSATSQSQWSCLAQKN-QRAIIQVWSGGYGMNNGVVSAIQAAQNAGFQVDLYAFLCNQCSPSSNVIQQIVSKIKQSGVSFGT--LWIDVEQCS---GCWG-STSANAAFVVEAVQTAAS-LGVRVGVYSSSGEWPQTVGTL-TSLSSYPQWYAHYDGVPAGQYGGWNNPEMKQYVGNTNQCGV--SVDLDFYG--------------
----TYGVDL------AGFQCLVGKGF-FAIVRCYMSSGGIDPNCASSVSAAWAGGMTVDLYLFPCFSCG----SLVQFAQS---NGVNFGK--IWLDIEGPG---TYWG-DQGANQQFFEGLVQGL--S-GVSVGIYTSESQWSPIMGDY-SGGSNFPLWYANYDGSPN-PFGGWSTPTMKQFDDPSN-CGI--GIDENWIG--------------
----GTGIDISSPTSKTQWSCLAKQN-TKAIIQVWSGGYGYNTNIASSVSAAKSAGIQVDLYAFLCSQCSPSSSAIKTLVSNLRSQNVEFGT--LWIDVEQCS---NCWG-STSTNAQFVVEAVQTAQQ-LGVSVGVYSSIGEWSQTVGSL-NSLSSFPLWYAHYDNVPASQFGSWSSPAMKQYAGNTQQCGV--SVDLDFFQ--------------... Contact maps Structure

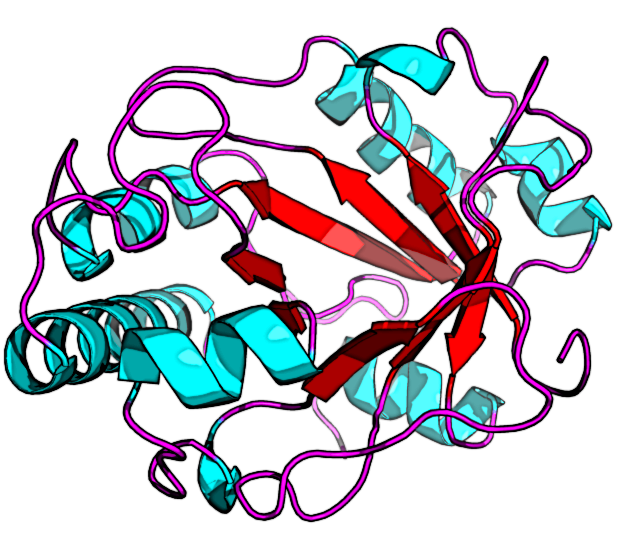
Top score model
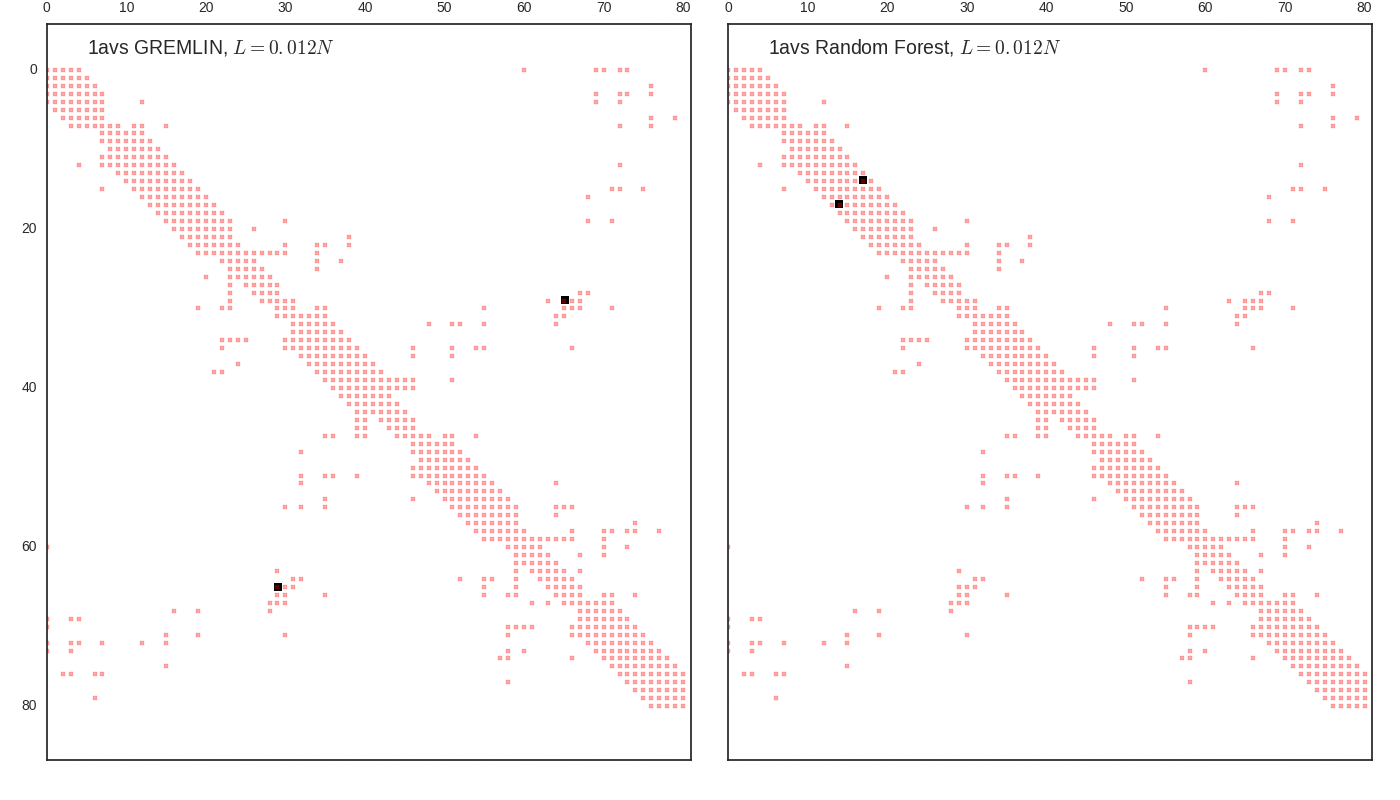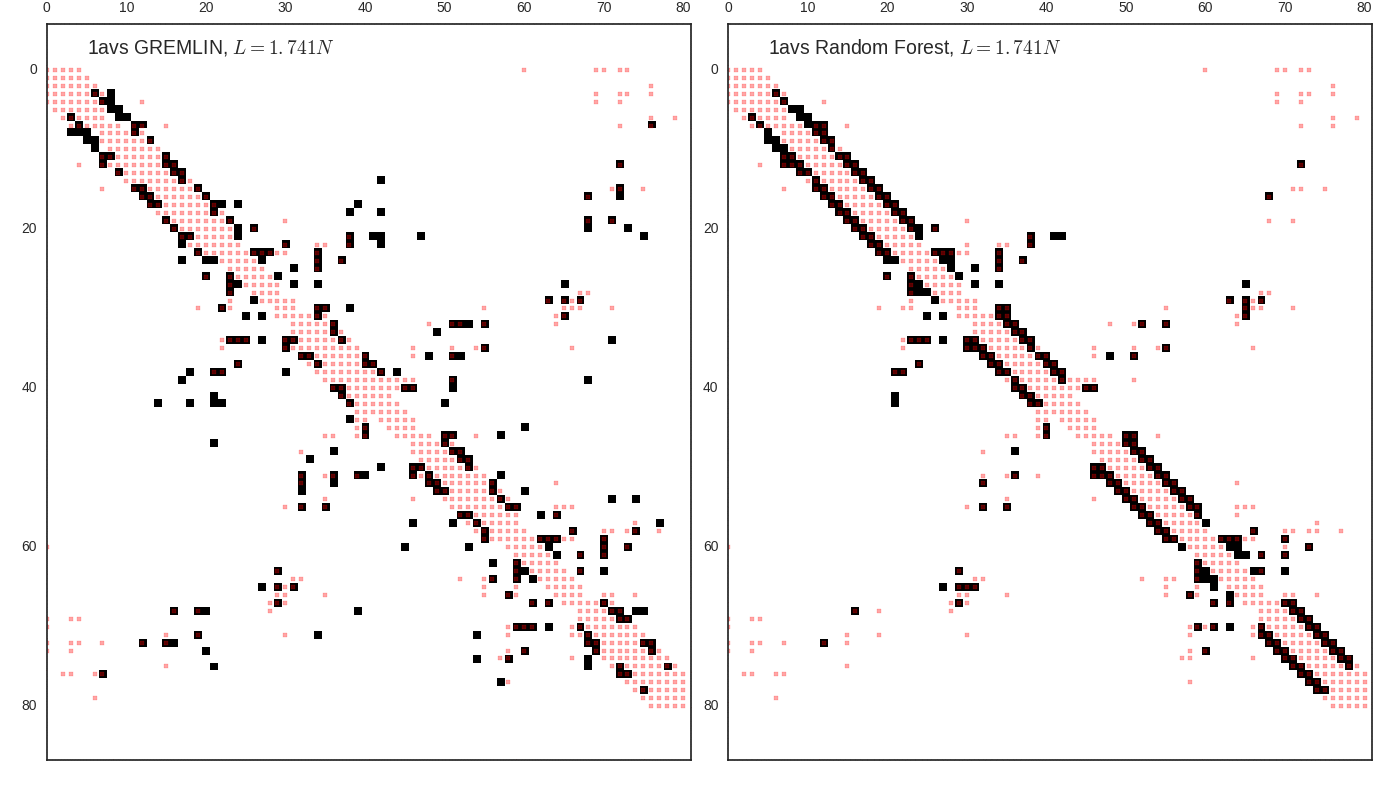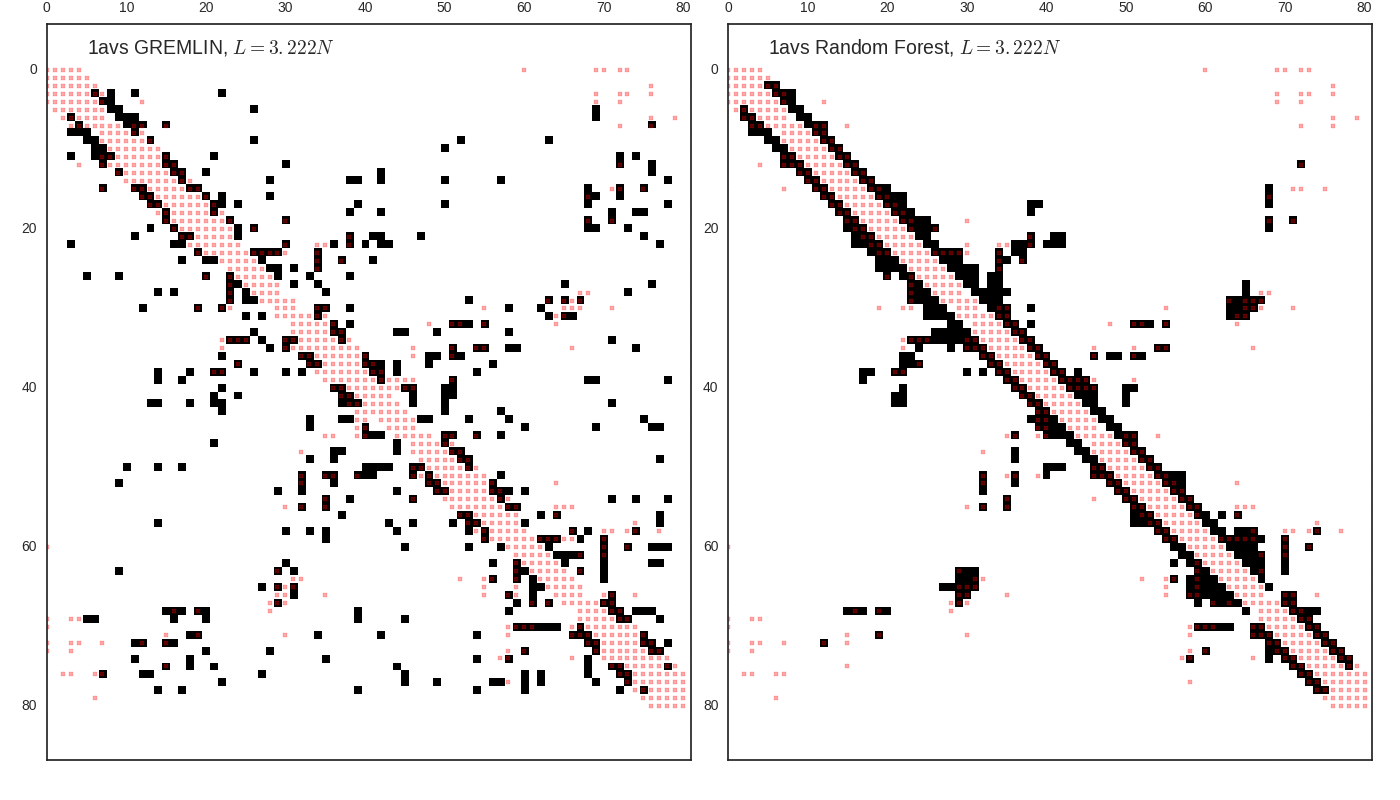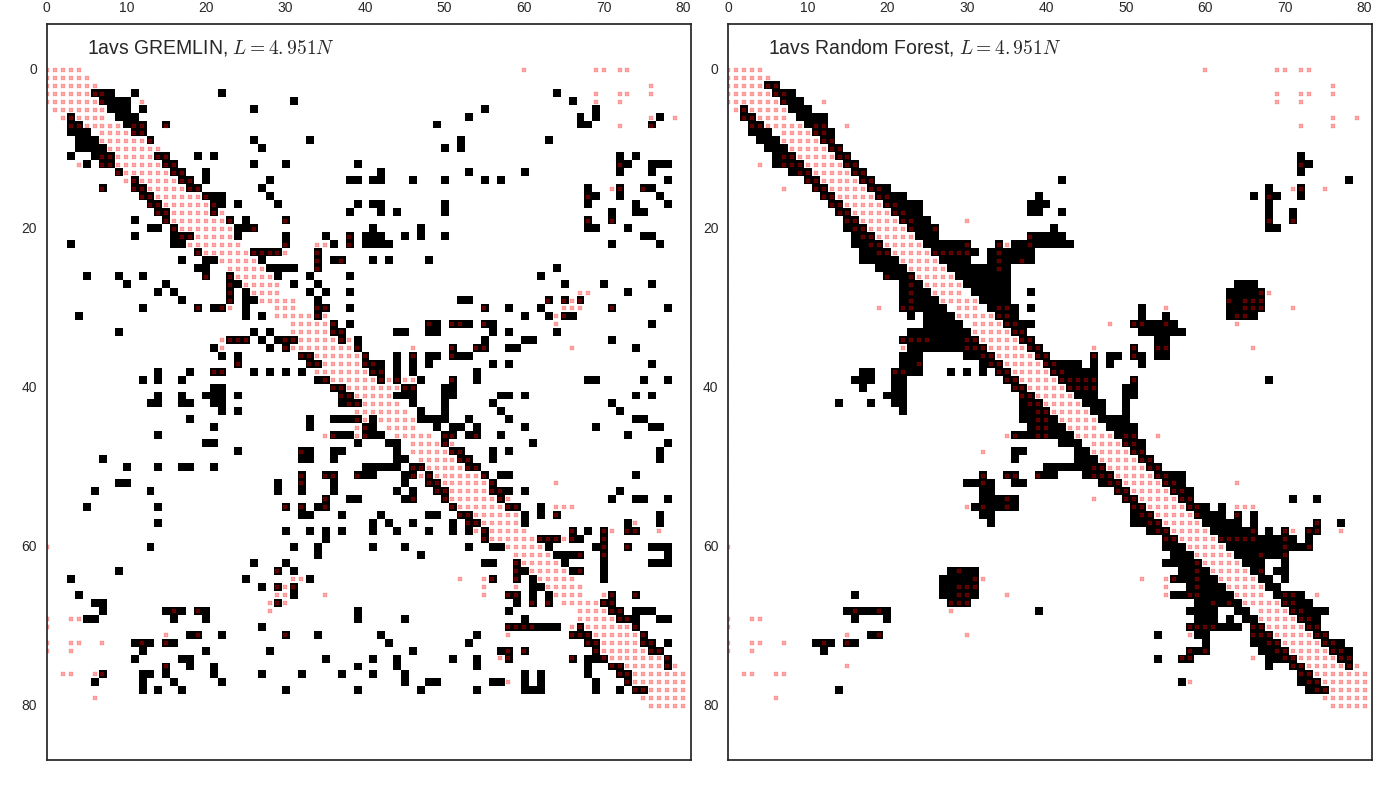
Rank sort top diagonal of , take top contacts.Typically values for .
Example proteins, GREMLIN APC corrected score
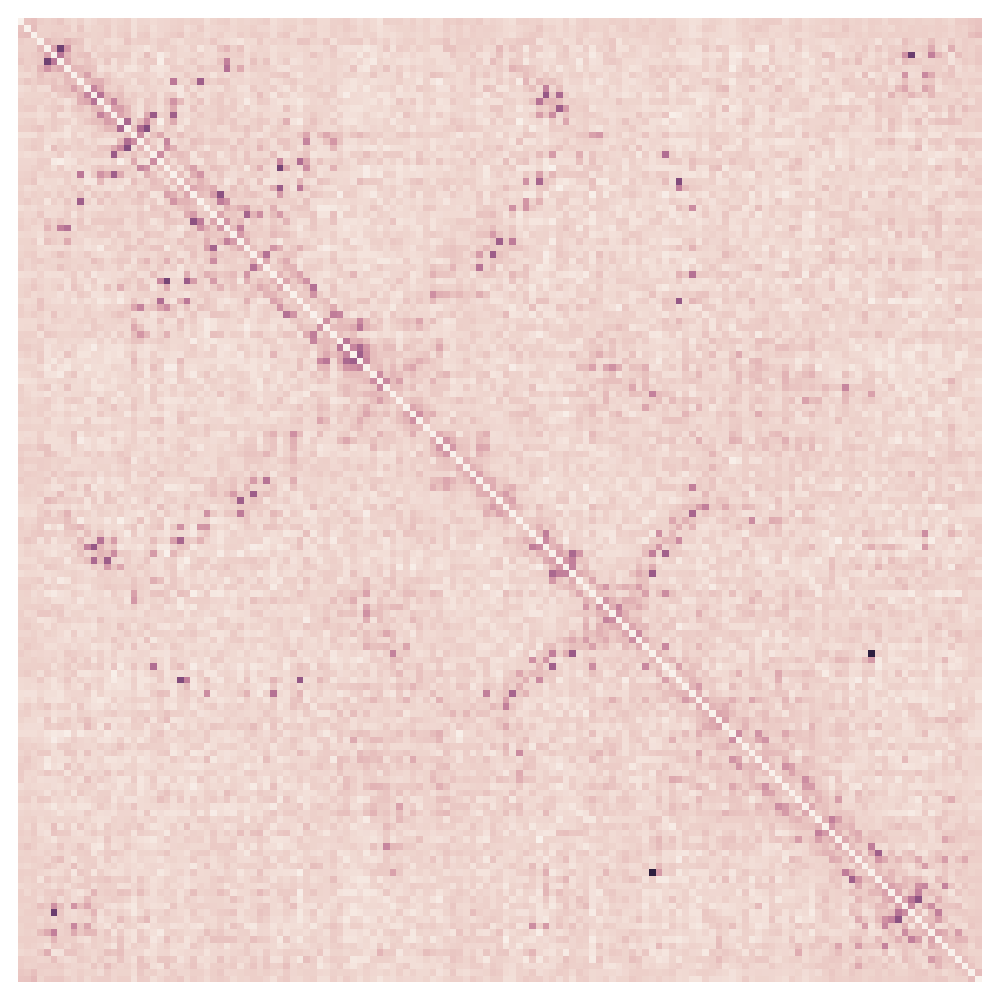
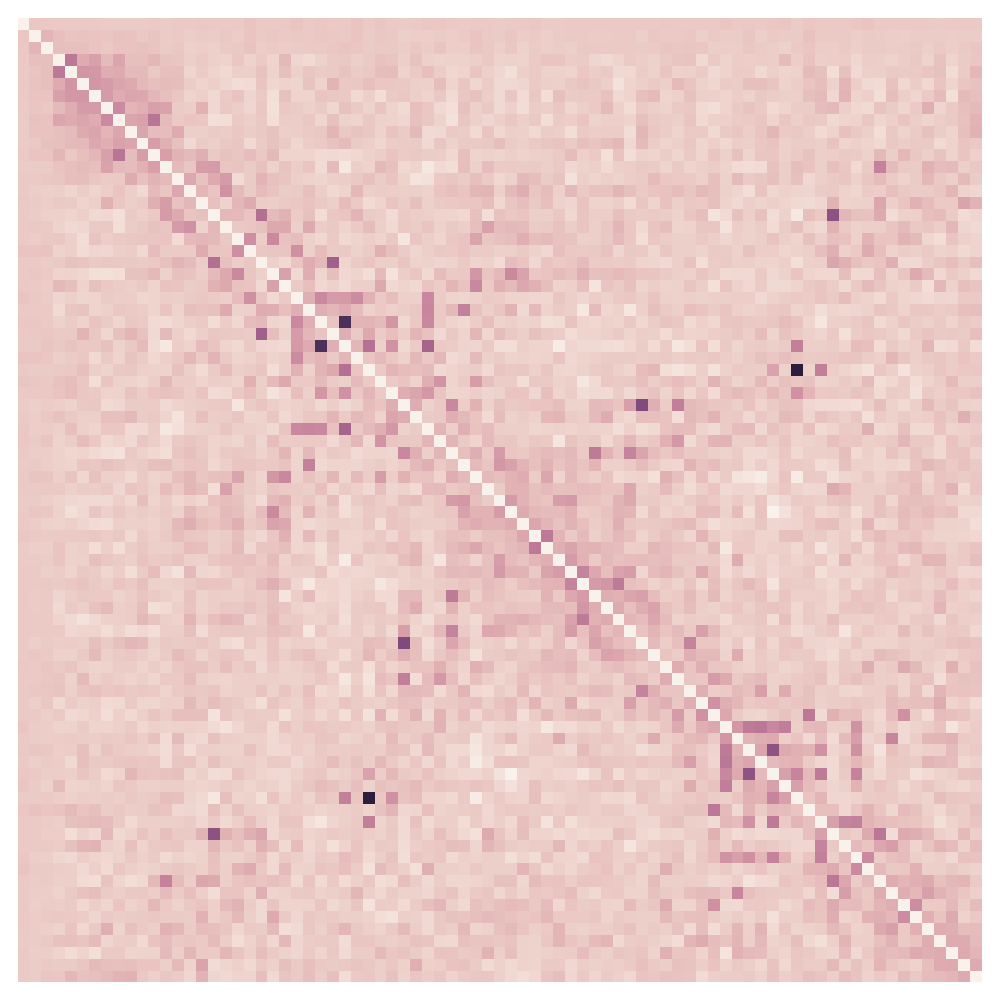
GREMLIN Predictions
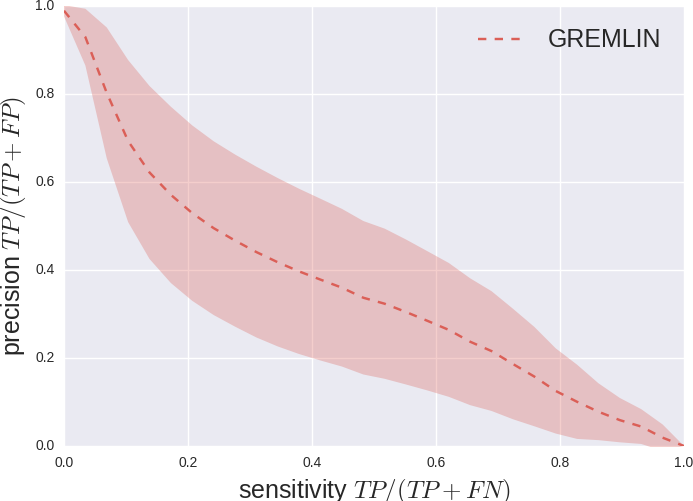
Hypothesis:
Local structure can enhance contact prediction.
Secondary structure is local (helices, sheets, turns).
What are Random Forests?
Decision trees are good for simple data, but tend to overfit.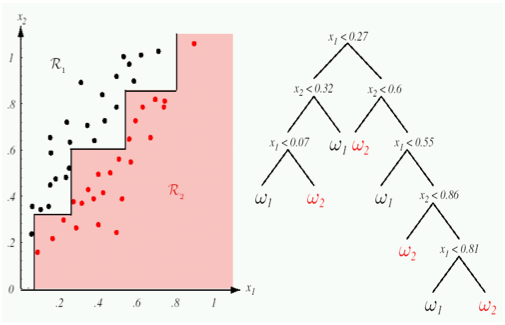
Random forests are multiple decision trees with 1] "random splits",
2] selective subsets, (each tree only gets to see a subset of the data).
This increases individual bias but the average corrects for overfitting.
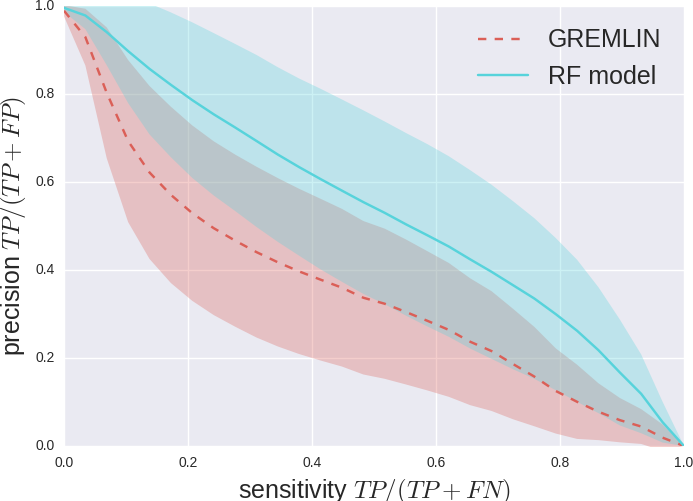
Improved RF model Predictions
Contact map vs cutoff length (1a3a)
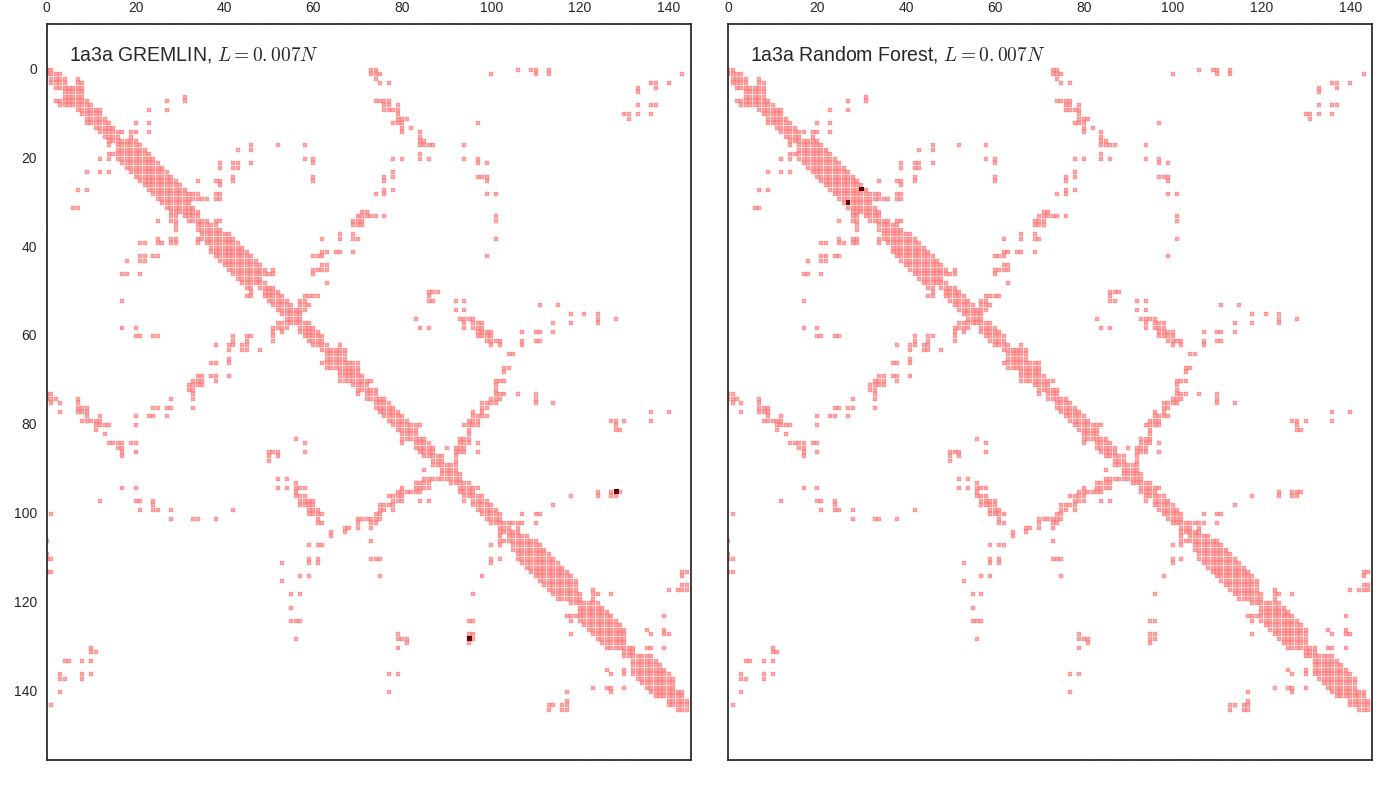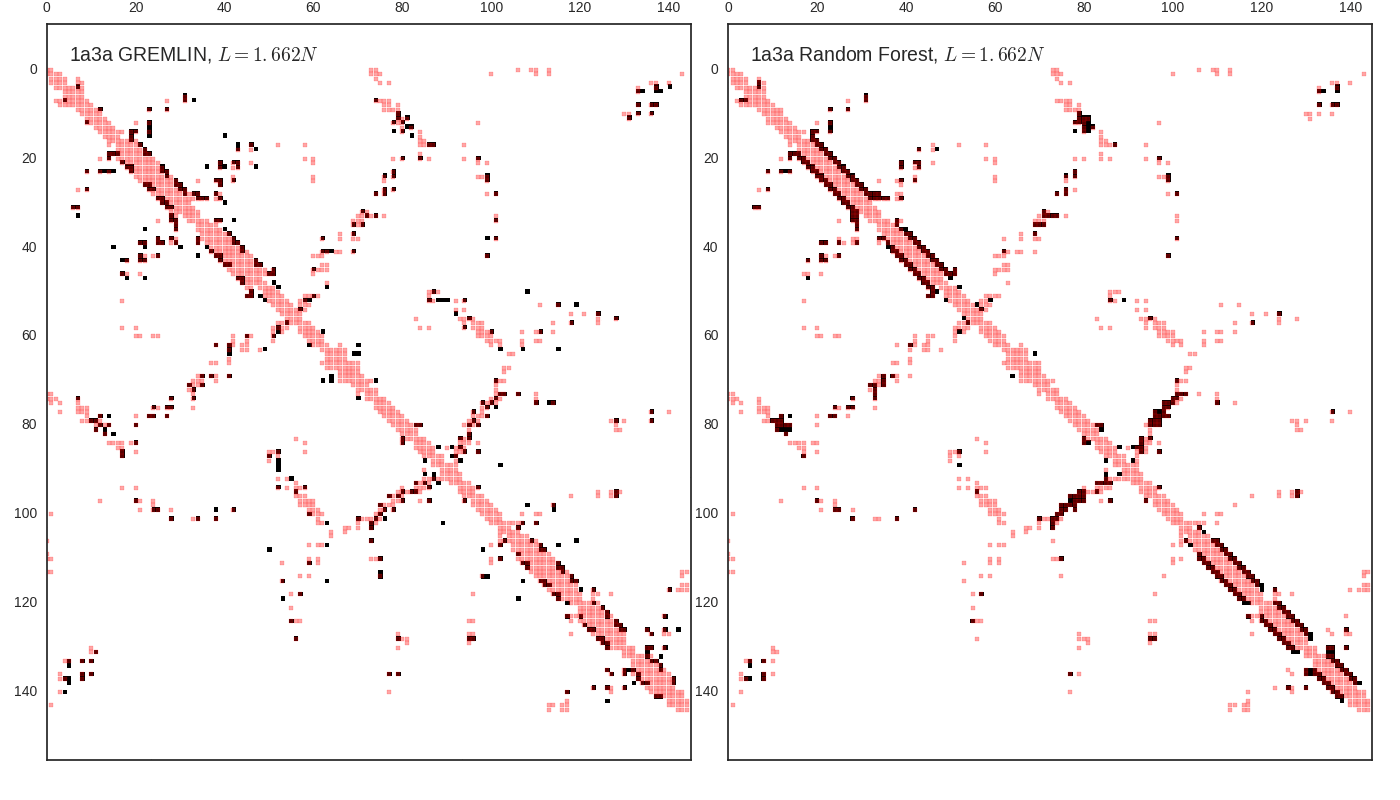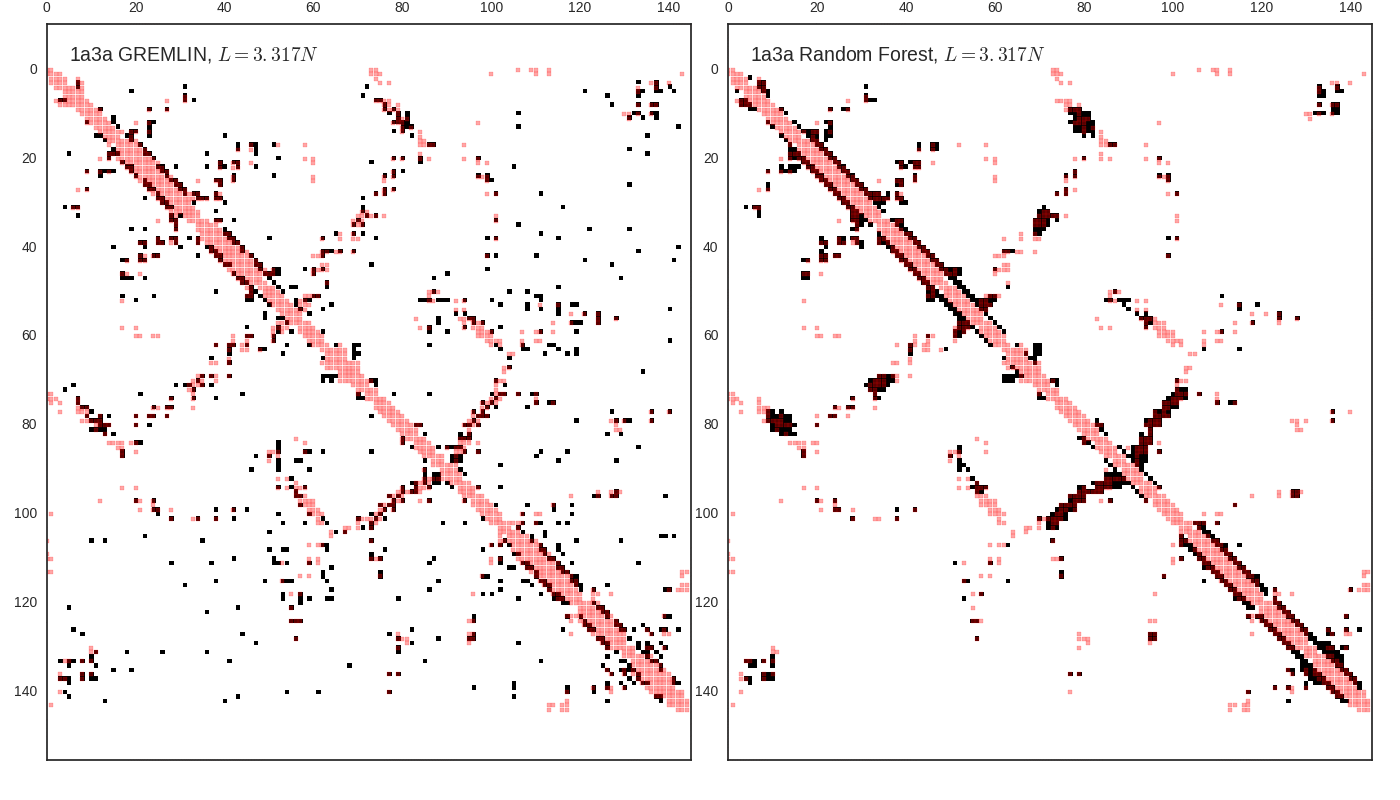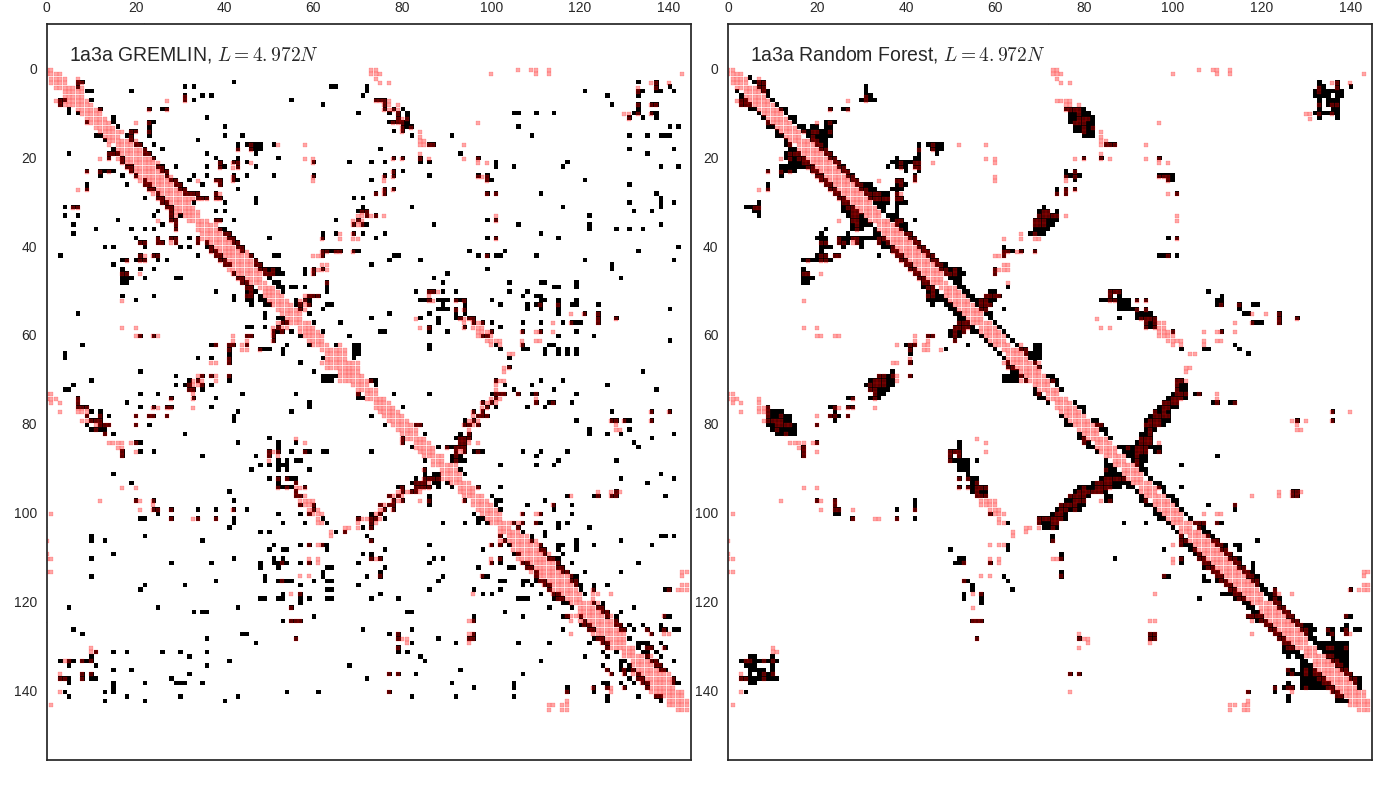
Contact map vs cutoff length (1avs)
Rapid collapse to contact potential
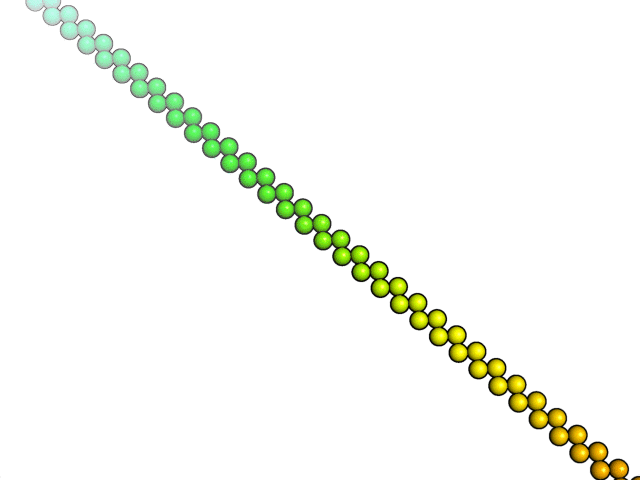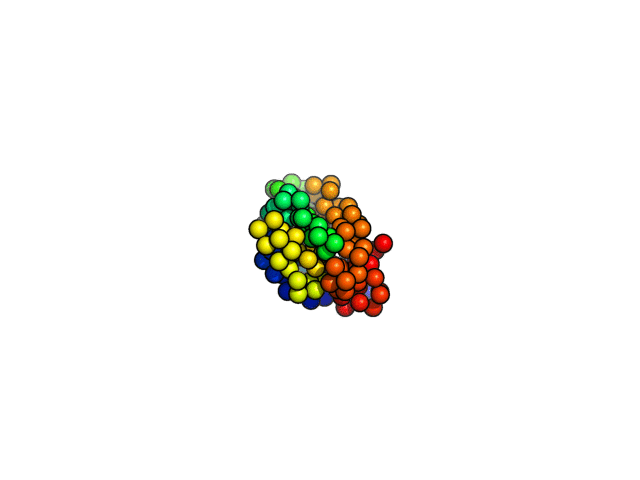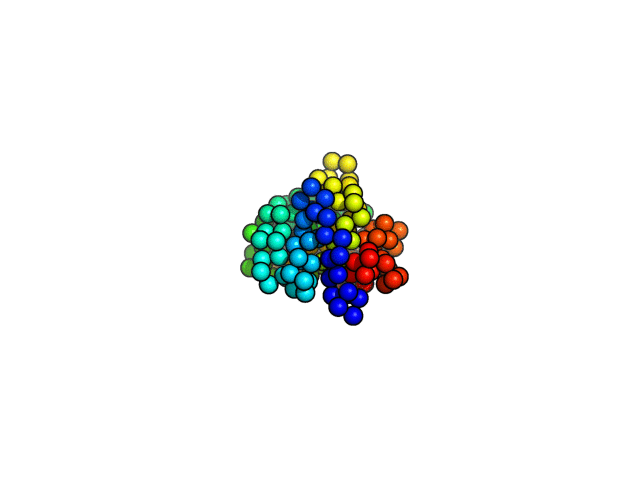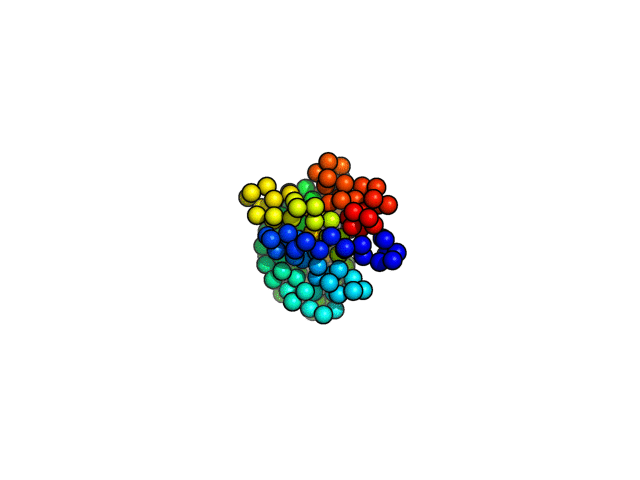
coarse-grained MD simulations
Folding simulations,
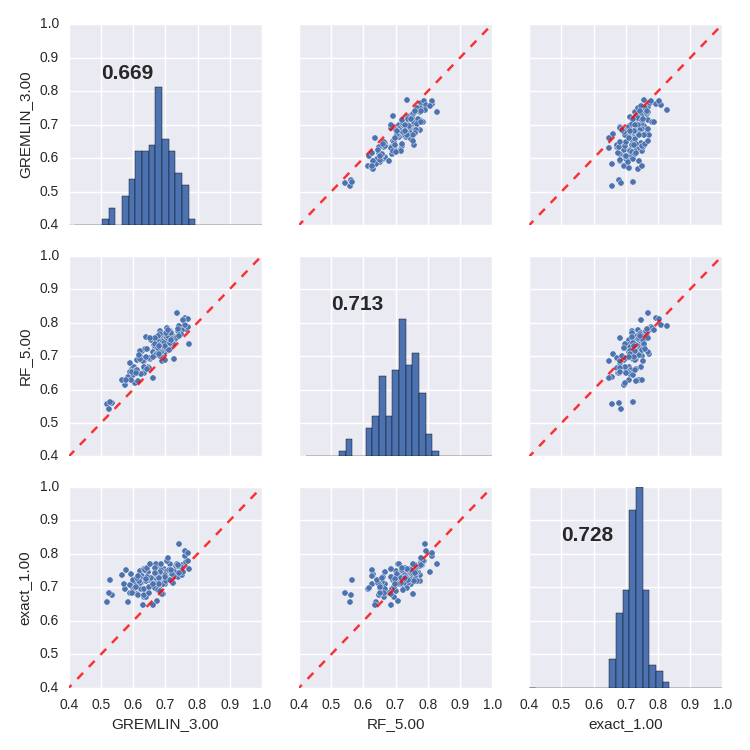
Predicted contacts are closer to true contacts
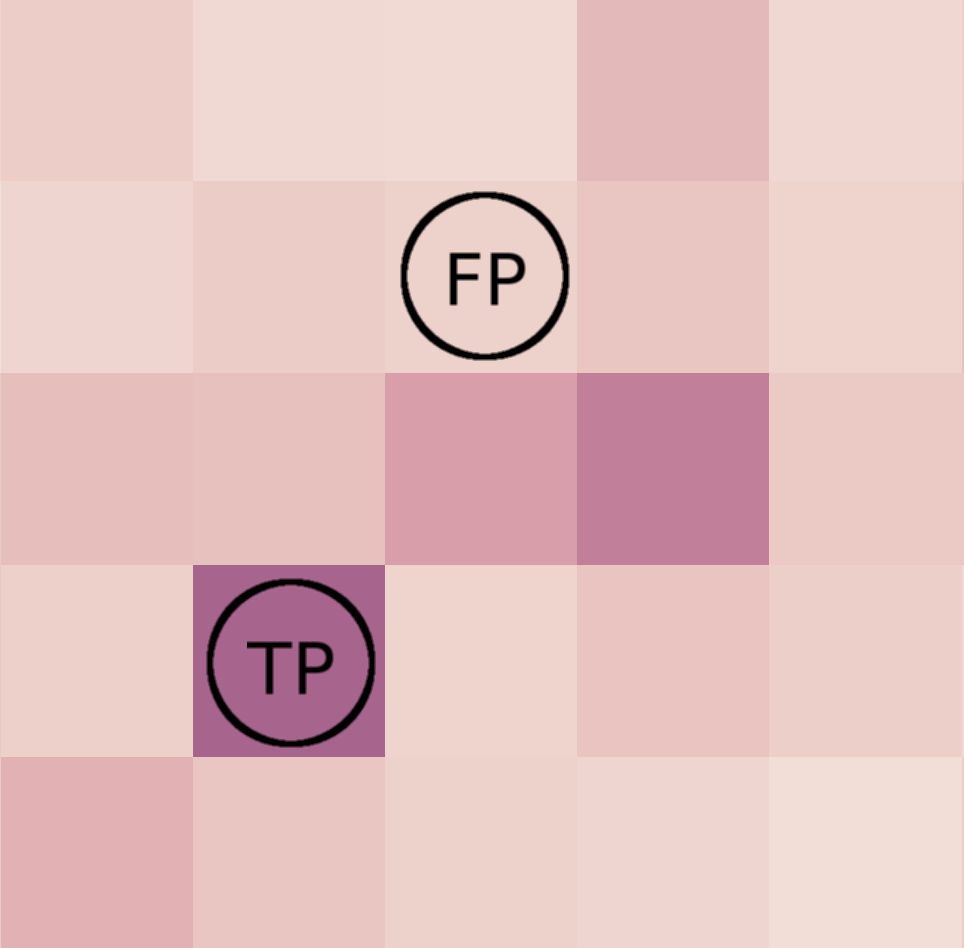
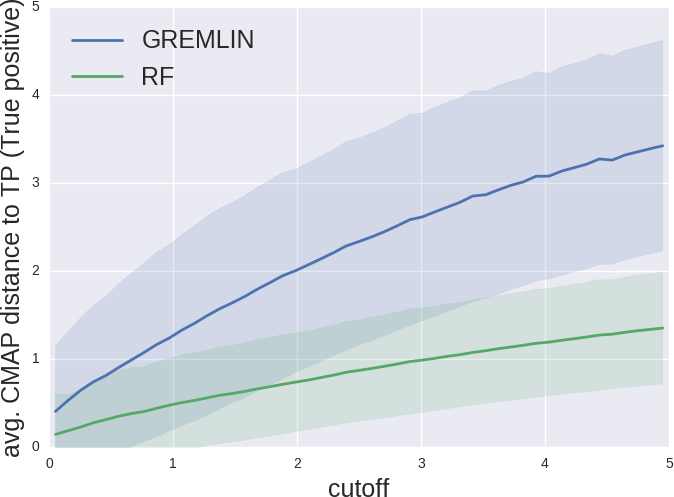
Improvement in folding
In potential, more contacts better RF fold.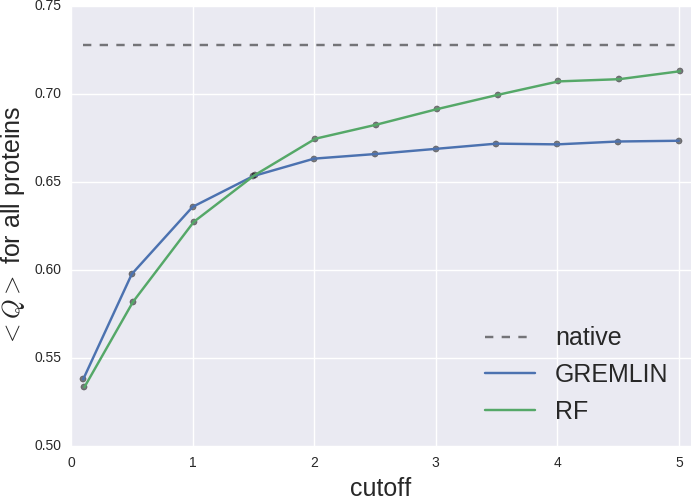
Random Forest features (central difference most important)
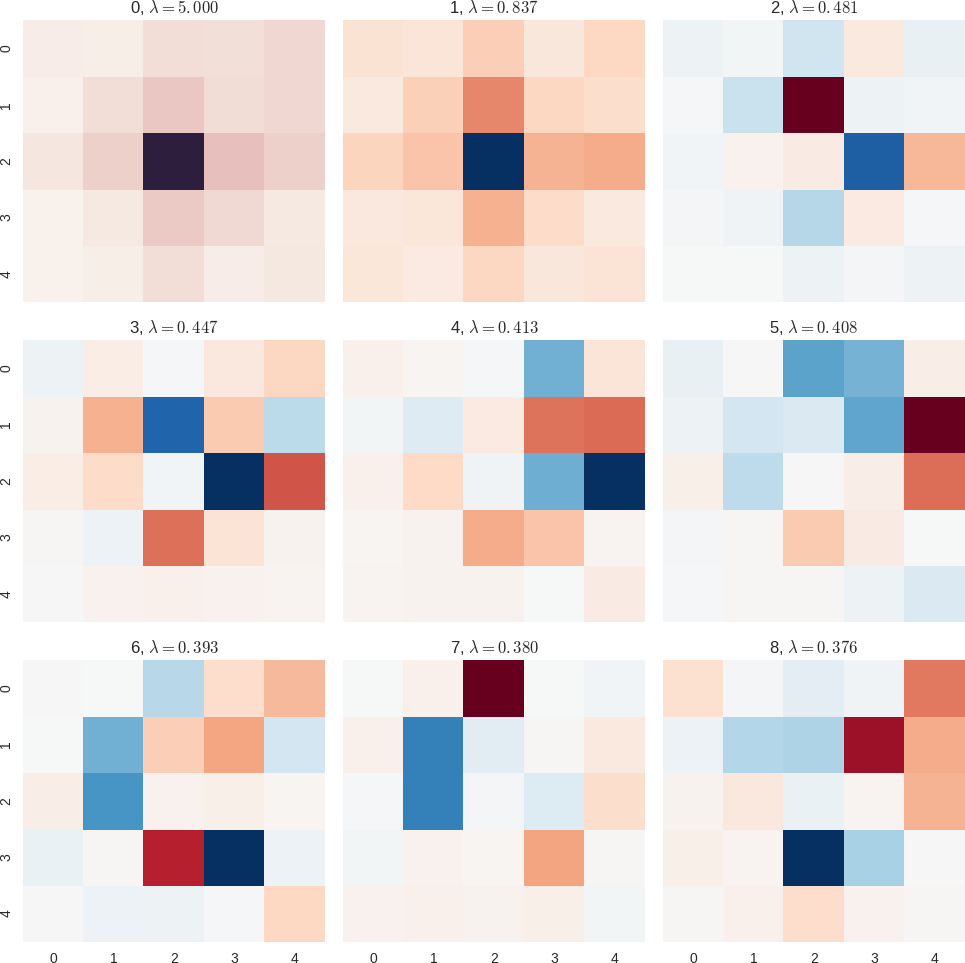
Future work & Extensions
Convolutional neural networks to improve prediction:
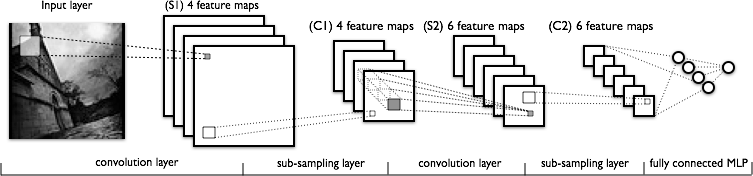
can be used as an effective Hamiltonian for evolutionary movement.